Alay Shah
Alay Shah
Home
Experience
Skills
Publications
Patents
Projects
Contact
Efficiency
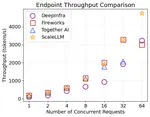
ScaleLLM: A Resource-Frugal LLM Serving Framework by Optimizing End-to-End Efficiency
In this work, we optimized both engine and platform. Our study reveals that with the growing complexity of LLM applications, the platform latency will be the major bottleneck. Our take being, instead of optimizing the local inference speed, the industrial research should focus more on simplifying the serving gateway and optimizing the platform.
Yuhang Yao
,
Han Jin
,
Alay Shah
,
Shanshan Han
,
Zijian Hu
,
Yide Ran
,
Dimitris Stripelis
,
Zhaozhuo Xu
,
Salman Avestimehr
,
Chaoyang He
PDF
Cite
Poster
Cite
×